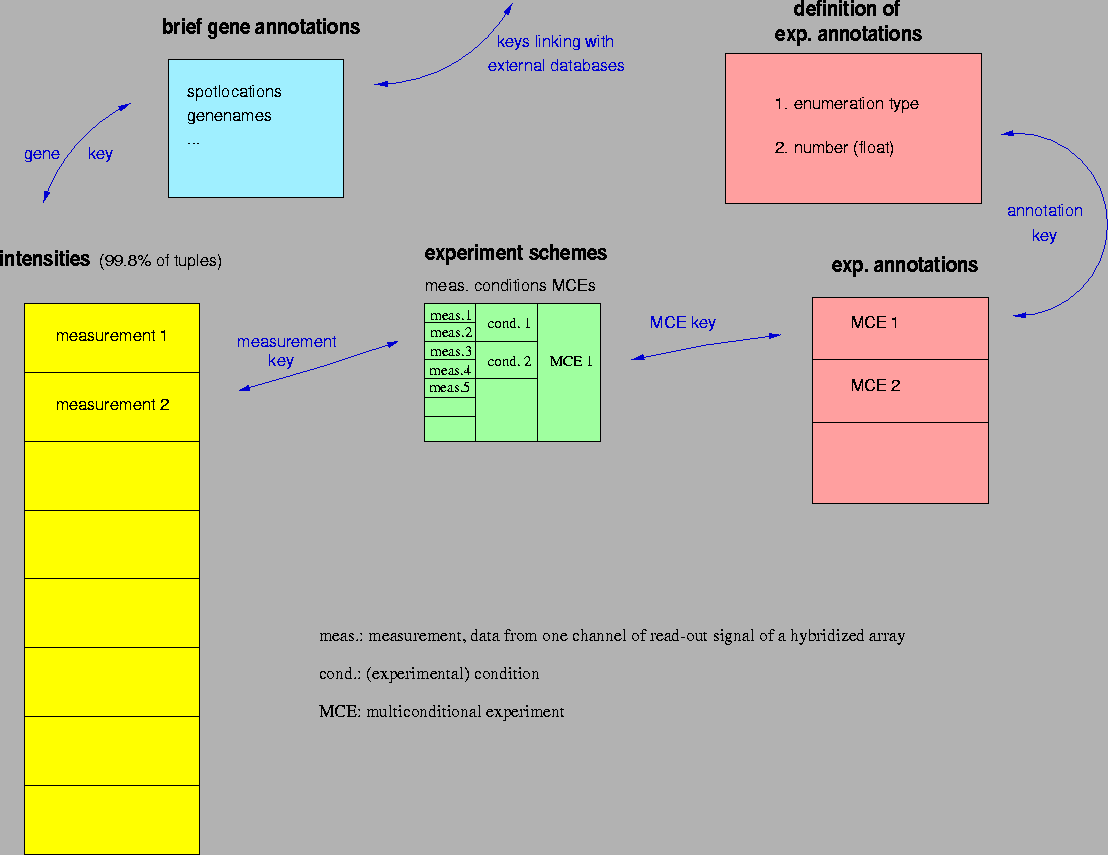
This chapter will deal with how to suit the action to the world proposing an implementation of the above concepts. I will start by describing database specific tables before showing schemes of the tables related to multiconditional experiments and hybridizations. The entirety of microarray data can be divided into the following sections. Each section is a subset of the one ahead of it in terms of hybridisation intensities, but comes along with a unique set of annotations:
| Section | Intensity Data | Annotations |
| database | containing all data derived from / related to one particular field of research (organism) | definition of valid experiment annotations along with a set of valid values for each of these annotations |
| microarray family | data obtained from one array type comprising a defined set of genes/ESTs in a particular spotting scheme | gene annotations (spot location, brief description and keys relating to external databases) |
| multiconditional experiment | set of measurements comprising two or more experimental conditions incl. one `control' condition | experiment annotations common throughout the experiment (unchanged in all of the conditions) |
| experimental condition | consists of one or more hybridizations repeatedly performed under the very same conditions | condition dependent experimental annotations (e.g. the timepoints in a timecourse) |
| measurement (image) | one image, i.e. one channel in case of multichannel data - consists of genes / ESTs, empty spots and different kinds of reference spots, all of which are spotted in duplicate (referred to as `primary' and `secondary' spots) | measurement dependent experiment annotations (e.g. labelling efficiency, individual array no., number of previously performed hybridisations on the individual array |
Our microarray databases are administered by a PostgreSQL database server process
running on a SUN E450. Data are uploaded, annotated and analyzed by users working
in different fields of research using samples from different organisms. A separate
database is created for each organism / field and endowed with particular definitions
of experimental annotations appropriate for the attended sort of sample. The
following scheme shows the definition of experimental annotations in relation
to other major parts and gives a rough overview of a database:
A detailed scheme is given at http://www.dkfz-heidelberg.de/tbi/services/mchips/scheme2.pdf. Apart from the experiment annotation definition-tables (red boxes on top), the latter scheme shows two more relations occuring only once per database (on top in green `DATABASE MANAGEMENT'-box). The first stores archive flags reporting any write access to either tables or BLOBSs (binary large objects) for an overnight job producing a new backup of the database. It also holds the database's structure version and nesting depth of its annotation hierarchy. The second is a register of the microarray families within the database.
|
Table = archive +----------------------------------+----------------------------------+-------+ | Field | Type | Length| +----------------------------------+----------------------------------+-------+ | tablesflag | bool | 1 | | blobsflag | bool | 1 | | structure_version | int4 | 4 | | headingsnestdepth | int4 | 4 | +----------------------------------+----------------------------------+-------+ Table = master +----------------------------------+----------------------------------+-------+ | Field | Type | Length| +----------------------------------+----------------------------------+-------+ | family | text | var | +----------------------------------+----------------------------------+-------+ |
The definition of experimental annotations consists of a table listing the annotations along with enumeration type values, a table containing the `annotation headings' which provide a hierarchy of topics categorizing the actual annotations, and one recording those annotations usually being measurement dependent:
|
Table = annotations +----------------------------------+----------------------------------+-------+ | Field | Type | Length| +----------------------------------+----------------------------------+-------+ | lastheadingno | int4 | 4 | | ano | int4 | 4 | | nextano | int4 | 4 | | annotation | text | var | | vno | int4 | 4 | | nextvno | int4 | 4 | | value | text | var | +----------------------------------+----------------------------------+-------+ Table = annotationheadings +----------------------------------+----------------------------------+-------+ | Field | Type | Length| +----------------------------------+----------------------------------+-------+ | heading1no | int4 | 4 | | heading1 | text | var | | heading2no | int4 | 4 | | heading2 | text | var | | heading3no | int4 | 4 | | heading3 | text | var | +----------------------------------+----------------------------------+-------+ Table = measdep_defaults +----------------------------------+----------------------------------+-------+ | Field | Type | Length| +----------------------------------+----------------------------------+-------+ | alwaysdep | int4 | 4 | +----------------------------------+----------------------------------+-------+ |
The annotation headings show a nesting depth of 3 heading levels.
Here the fourth level of the hierarchy comprises the annotations themselves,
the fifth their annotation values. For the annotation of an experiment the nested
headings and annotations are compiled into one HTML form by a web interface.
To accelerate the recursive CGI script, starting and end points of blocks consisting
of elements to be sequentially listed in the form (but not necessarily being
sequentially numbered in the linked list), are precompiled into arrays and recorded
after updating the definition tables:
|
Table = minnext +----------------------------------+----------------------------------+-------+ | Field | Type | Length| +----------------------------------+----------------------------------+-------+ | j | int4 | 4 | | h1 | text | var | | h2 | text | var | | h3 | text | var | | ano | text | var | | vno | text | var | +----------------------------------+----------------------------------+-------+ Table = maxnext +----------------------------------+----------------------------------+-------+ | Field | Type | Length| +----------------------------------+----------------------------------+-------+ | j | int4 | 4 | | h1 | text | var | | h2 | text | var | | h3 | text | var | | ano | text | var | | vno | text | var | +----------------------------------+----------------------------------+-------+ |
To give an expample how experiment annotation definitions may look like in practice, I will list the first part of common annotations (used commonly for yeast, arabidopsis and human cancer biopsies to describe the more technical part of the experiment):
|
yeast=> select * from annotationheadings order by heading1no, heading2no, heading3no; heading1no|heading1 |heading2no|heading2 |heading3no|heading3 ----------+-----------------------------+----------+-----------------+----------+------------------------------------ 1|common_annotations | 1|array | 1|- 1|common_annotations | 2|hybridisation | 2|RNA_preparation 1|common_annotations | 2|hybridisation | 3|labeling 1|common_annotations | 2|hybridisation | 4|hybridisation_conditions 1|common_annotations | 2|hybridisation | 5|stringency_wash 1|common_annotations | 2|hybridisation | 6|detection 1|common_annotations | 3|sample | 7|- 1|common_annotations | 4|submission | 8|- 2|organism_specific_annotations| 5|genotype | 9|- ... skipping ... yeast=> select * from annotations order by lastheadingno, ano, vno; lastheadingno| ano|nextano|annotation | vno|nextvno|value -------------+----+-------+-----------------------------------+----+-------+----------------------------------------- 1| 1| 2|array_source | 10| 11|self_made 1| 1| 2|array_source | 11| 12|genome_systems 1| 1| 2|array_source | 12| 13|clontech 1| 1| 2|array_source | 13| 14|research_genetics 1| 2| 3|array_series | 0| 0|[] 1| 3| 4|array_individual | 0| 0|[] 1| 4| 5|array_support | 14| 15|nylon 1| 4| 5|array_support | 15| 16|polypropylene 1| 4| 5|array_support | 16| 17|glass 1| 5| 6|spotted_material | 17| 18|PCR 1| 5| 6|spotted_material | 18| 19|colonies 1| 5| 6|spotted_material | 19| 20|DNA-oligo 1| 5| 6|spotted_material | 20| 21|PNA-oligo 1| 6| 7|readfile | 0| 0|[] 1| 7| 8|array_hybridisation | 0| 0|[] 2| 8| 9|material_source | 21| 22|fresh 2| 8| 9|material_source | 22| 23|frozen ... skipping ... |
The complete set of common annotations can be found in the first part of each annotation definition list on our web site, e.g. in the yeast list (HTML, text). The actual experiment annotations which are entered via similar HTML forms are stored elsewhere as described below (3.3.1, 3.4.2 and 3.5.3).
A database can comprise different sorts of microarrays. Each family represents
a unique spotting scheme including genes or ESTs and reference spots. For a
family referred to as 'y1' by the master table of the database yeast, there
are 5 gene annotation tables corresponding to the categories mentioned in 2.2.1:
| category | table name |
| genes | y1_genes |
| empty spots | y1_empty |
| heterologous DNA | y1_hetrl |
| heterologous DNA with known concentration | y1_hetkc |
| reference spots | y1_refgs |
All of these tables share the same scheme:
|
Table = y1_genes +----------------------------------+----------------------------------+-------+ | Field | Type | Length| +----------------------------------+----------------------------------+-------+ | spotno | int4 | 4 | | field | int4 | 4 | | plate | int4 | 4 | | letter | char() | 1 | | number | int4 | 4 | | ext_link7 | char() | 7 | | ext_link10 | char() | 10 | | partition | int4 | 4 | | description | text | var | | functional_catalogue | text | var | +----------------------------------+----------------------------------+-------+ Indices: y1_genes_isn y1_genes_if y1_genes_ip y1_genes_il y1_genes_in y1_genes_in7 y1_genes_in10 y1_genes_ipart y1_genes_id y1_genes_ifc |
An index has been computed for every attribute with the name of each index relation consisting of the family, the spot category and an abbreviation of the indexed attribute (attributes and their indexes are listed in the same sequence).
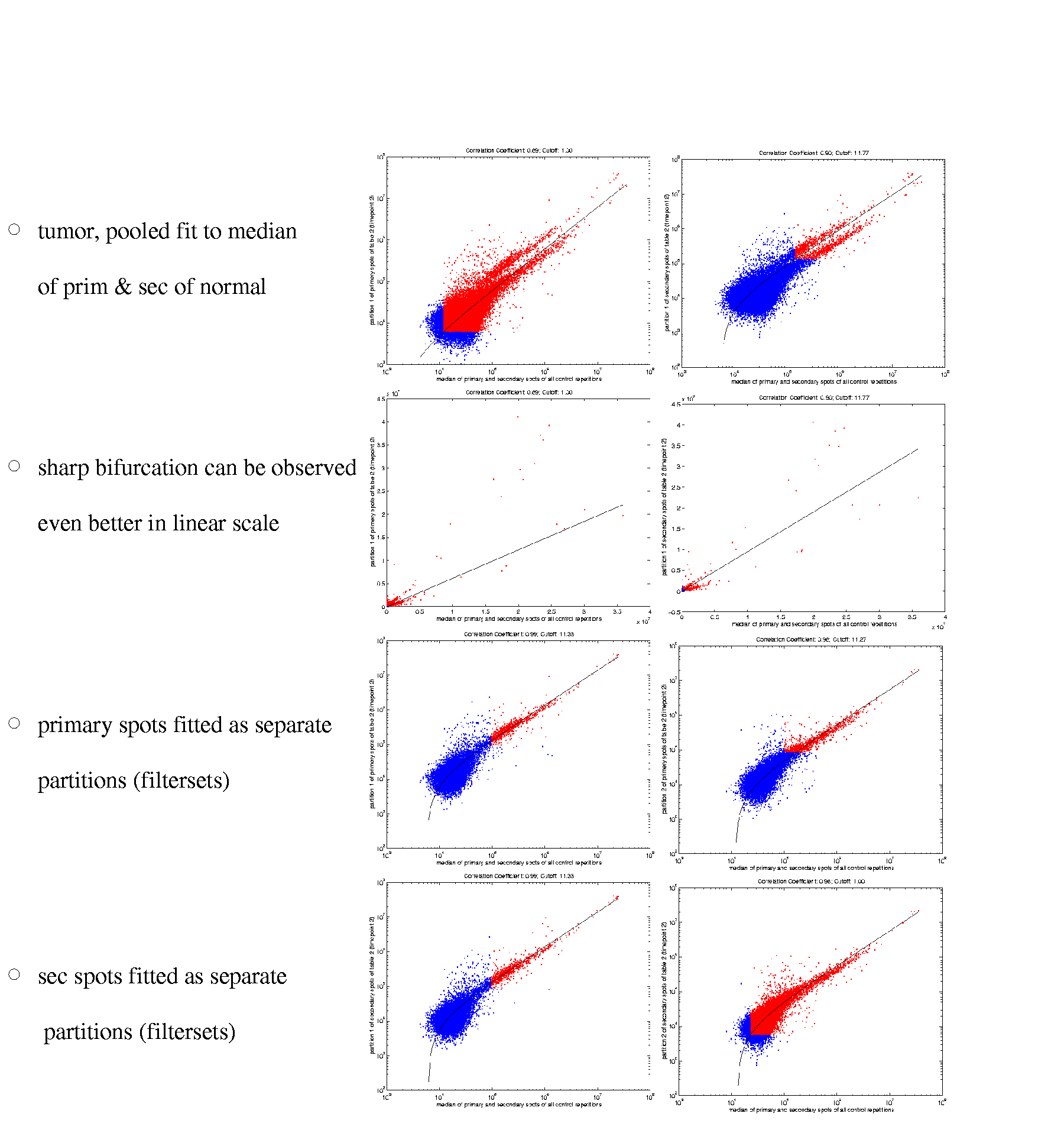
The attribute 'spotno' serves as a key connecting to the tables which contain hybridisation intensities. 'field', 'plate', 'letter' and 'number' correspond to the spot location on the array as well as to the DNA stock kept in microtiter plates. Two fields of fix length ('ext_link7' and 'ext_link10') are reserved for keys linking to external databases and 'description' and 'functional_catalogue' contain a brief description of the protein and its function of variable form and size. Certain spotsets may have to be normalized separately. In such cases the partition of the spots is recorded by the attribute `partition'. In the example given below, which was taken from the database 'humanbiopsy' (containing data derived from renal clear cell carcinoma, family 'hb1'), there are two partitions of the entire set leading to a `bifurcation' of data points in a scatter plot.
In this example the partitions correspond to the location of the spots on two different nylon filters (the spotset being too big to be spotted on one filter) which have to be hybridised in separate tubes.
There are two more tables belonging to an array family (see detailed scheme, also in 'DATABASE MANAGEMENT'). To stick to the example family 'y1' (comprehensive yeast filter), there is a table named 'y1'
|
Table = y1 +----------------------------------+----------------------------------+-------+ | Field | Type | Length| +----------------------------------+----------------------------------+-------+ | experiments | int4 | 4 | | tables | int4 | 4 | | i_fileformat | int4 | 4 | +----------------------------------+----------------------------------+-------+ |
storing the number of multiconditional experiments as well as the number of measurements in the family. Since each measurement is initially stored in a separate table (see 3.5.1) and identified with a unique table number, their quantity is attributed as `tables'. Generally, `measurement' 5 identifies the 5th measurement of a particular experiment (see 3.4.1), whereas `tables' / `tableno' hold quantity / IDs of measurements on a family-wide scale (even when the initial tables have been merged into a block).
The third attribute (`intput file format') stores the version number of the script capable of reformatting an output file of a particular imaging software into the format of a database table. This matlab function exists in different versions enumerated sequentially for different imaging software types and spotting schemes.
The second table lists the multiconditional experiments contained by the family.
|
Table = y1_master +----------------------------------+----------------------------------+-------+ | Field | Type | Length| +----------------------------------+----------------------------------+-------+ | experiment | int4 | 4 | | ex_name | text | var | | ex_table | int4 | 4 | | conditions | int4 | 4 | | condep_ano | text | var | +----------------------------------+----------------------------------+-------+ Indices: y1_master_iex y1_master_ien y1_master_iet y1_master_ico y1_master_ica |
Each experiment is assigned a number and a name. 'ex_table' links to the administration table for the hybridisation intensities as well as to the experimental annotations. For convenience in algorithmical handling, we redundantly included here also the number of comprised conditions as well as the varied experimental parameters ('condition-dependent annotations').
There may be an arbitrary number of multiconditional experiments hybridised on a particular filter family. They may be timecourses, variations of agent concentrations in culture media, comparisons of different genotypes just to give some examples, consisting of several experimental conditions intended to be directly comparable. To learn something from such a comparison not too many parameters should be altered among the conditions performed. Hence most of the experimental conditions are constant for the entire experiment, some are condition dependent and some are measurement dependent, i.e. they can take different values for each single measurement, like e.g. the label incorporation rate. For fast annotation via html questionaire, the data are required in the form of these three sets of annotations. For statistical analysis, they are needed hybridization wise. Redundancy caused by hybridization wise storage of the entire set of annotations would have little effect in terms of storage space or performance because these annotations are of negligible volume. However, we decided to store them in separate relations for convenient algorithmical handling: Splitting up a uniform set of hybridization wise stored annotations into hybridization-dependent, condition-dependent and constant annotations requires repeated value comparison, whereas the distribution of constant and condition-dependent annotations to each hybridization is a trivial task.
Constant annotations are stored in two separate tables per multiconditional experiment just to be more readable rather than for computational reasons. These tables are children of parental tables `y1_constant_categoricalvalue' and `y1_constant_number' respectively. The numbers within their names as well as the content of the field 'experiment' correspond to the according key in y1_master.
|
Table = y1_constant_categoricalvalue_65 +----------------------------------+----------------------------------+-------+ | Field | Type | Length| +----------------------------------+----------------------------------+-------+ | experiment | int4 | 4 | | ano | int4 | 4 | | annotation | text | var | | vno | int4 | 4 | | cvalue | text | var | +----------------------------------+----------------------------------+-------+
|
The first table takes the enumeration type (`categorical') annotations, the second one those consisting of a number. This is reflected by the type of the attributes `cvalue' and `nvalue' which is the only difference among the above schemes. As a representative of intended redundancy both number (`ano') and name (`annotation') are enlisted for an annotation as well as for its value. For the small extent of the annotations (1.3.2.2) this does not have major consequences for storage space nor for performance. However the redundancy might serve to reconstruct experimental annotations (which would be very time consuming to re-enter by hand) if an error occurs in the numbering of annotations or values. Redundant storage appears advisable here because as new kinds of experiments evolve, annotation definitions are under constant change.
For each condition in a multiconditional experiment, there is a table like the following which for our example family y1 inherits from a parental relation y1_experiment. For the above experiment no. 65 it will be named y1_ex_65.
|
Table = y1_experiment_65 +----------------------------------+----------------------------------+-------+ | Field | Type | Length| +----------------------------------+----------------------------------+-------+ | experiment | int4 | 4 | | condition | int4 | 4 | | hybridization | int4 | 4 | | measurement | int4 | 4 | | tableno | int4 | 4 | +----------------------------------+----------------------------------+-------+ |
'experiment' will contain a 65 as well for the entirety of tuples to identify the experiment in a family-wide context, since the experiment tables can be merged into big block relations as for the intensities (see 2.2.2, 3.5.2). The comprised conditions have been studied by several repeatedly performed hybridizations which themselves consist of one (radioactive labelling, monochannel) or more (multichannel fluorescence data) measurements (frequently called channels or images). While 'measurement' identifies a measurement in the context of its particular experiment, 'tableno' holds its family-wide ID. Both remain unchanged when the initial tables are merged into a block.
The number of successfully performed hybridizations and measurements may vary among the conditions. As an example we show the content of the above relation which outlines an experiment with radioactive (monochannel) hybridizations:
|
yeast=> select * from y1_experiment_65 order by tableno; experiment|condition|hybridization|measurement|tableno ----------+---------+-------------+-----------+------- 65| 0| 1| 1| 576 65| 0| 2| 2| 577 65| 0| 3| 3| 578 65| 1| 4| 4| 579 65| 1| 5| 5| 580 65| 1| 6| 6| 581 65| 2| 7| 7| 582 65| 2| 8| 8| 583 65| 2| 9| 9| 584 65| 2| 10| 10| 585 65| 2| 11| 11| 586 65| 3| 12| 12| 587 65| 3| 13| 13| 588 65| 3| 14| 14| 589 65| 3| 15| 15| 590 65| 3| 16| 16| 591 (16 rows) |
The control condition is identified by a zero whereas numbering of hybridizations and measurements starts at one. While in the above case the measurement IDs correspond to those of the hybridizations, they are different in multichannel experiments where each hybridization comprises more than one measurement belonging to different conditions. Whereas the sequence recorded in `measurement' is due to the experiment (with the first one of a hybridization usually being the `red' channel), the purpose of `tableno' is rather technical. It simply corresponds to the order in which they were uploaded into the database, being a unique ID.
The condition dependent annotations describing experiment no. 65 are stored in y1_conditiondependent_65.
|
Table = y1_conditiondependent_65 +----------------------------------+----------------------------------+-------+ | Field | Type | Length| +----------------------------------+----------------------------------+-------+ | experiment | int4 | 4 | | condition | int4 | 4 | | ano | int4 | 4 | | annotation | text | var | | vno | int4 | 4 | | cvalue | text | var | | nvalue | float8 | 8 | +----------------------------------+----------------------------------+-------+ |
It shows the same structure as for the constant annotations (described in 3.3.1), except for including both numbers (stored in 'nvalue') and enumeration type values (in 'cvalue') into one table. Moreover it contains an additional attribute accounting for the condition. Enumeration of conditions starts at zero for the control condition.
|
yeast=> select * from y1_conditiondependent_65 order by ano, condition, vno; experiment|condition| ano|annotation | vno|cvalue |nvalue ----------+---------+----+-----------------+----+------------------+------ 65| 0|1035|strain |1091|3E2 |NaN 65| 1|1035|strain |1091|3E2 |NaN 65| 2|1035|strain |1092|702 |NaN 65| 3|1035|strain |1092|702 |NaN 65| 0|1037|genetic_variation|1100|WT |NaN 65| 1|1037|genetic_variation|1100|WT |NaN 65| 2|1037|genetic_variation|1099|inducible_promoter|NaN 65| 3|1037|genetic_variation|1099|inducible_promoter|NaN 65| 0|1038|transgene | 0|*** |0 65| 1|1038|transgene | 0|*** |0 65| 2|1038|transgene | 0|*** |4111 65| 3|1038|transgene | 0|*** |4111 65| 0|1049|glucose | 0|*** |2 65| 1|1049|glucose | 0|*** |0 65| 2|1049|glucose | 0|*** |2 65| 3|1049|glucose | 0|*** |0 65| 0|1050|galactose | 0|*** |0 65| 1|1050|galactose | 0|*** |2 65| 2|1050|galactose | 0|*** |0 65| 3|1050|galactose | 0|*** |2 (20 rows) |
In this particular experiment both the genotype of the yeast cells and the carbon source of their medium had been varied. For enumeration type annotations like 'strain', a valid valuenumber ('vno') is listed but the field 'nvalue' contains 'not-a-number'. Conversely, floating point number annotations like 'transgene' or 'glucose' have valueno 0 and a dummy entry for 'cvalue', but a meaningful 'nvalue' (namely the floating point value, wich happens to be always a natural number in the above table).
Like in the above tables, a field is included that denotes the experiment number for every tuple for identification in block context. The according parental tables (in the above case `y1_conditiondependent' is the name of the parent) are themselves empty but mediate queries on all of their children (see in 2.2.2). This means that the query syntax given on top of the table list is never used. Instead all the algorithms involved would query this table by
yeast=> select * from y1_conditiondependent* where ex=65 order by ano, condition, vno;
resulting in the very same list.
As listed in the administration table for experiment 65 (see 3.4.1), the third measurement of the last condition is hybridisation number 589. The corresponding intensities are stored in 5 separate tables (compare 2.2.1 & 3.2.1), being accessed via the parental tables `y1_g', `y1_e', `y1_h', `y1_k' and `y1_r'. They are of a uniform structure they inherited from their uniform parents, one example being:
|
Table = y1_g_589 +----------------------------------+----------------------------------+-------+ | Field | Type | Length| +----------------------------------+----------------------------------+-------+ | tableno | int4 | 4 | | spotno | int4 | 4 | | prim | float8 | 8 | | sec | float8 | 8 | | prim_bkg | float8 | 8 | | sec_bkg | float8 | 8 | +----------------------------------+----------------------------------+-------+ Indices: y1_g_589_ipr y1_g_589_ise y1_g_589_isn |
Since this kind of tables is also accessed by querying the parental table, `tableno' mediates identification in block context, linking to the administration table (y1_experiment). `Spotno' identifies the spot, corresponding to the identically named attribute of the gene annotation table `y1_genes' (3.2.1). In the tables `y1_e_589', `y1_h_589', `y1_k_589' and `y1_r_589' this attribute corresponds to the `spotno' in `y1_empty', `y1_hetrl', `y1_hetkc' and `y1_refgs', respectively. The remaining attributes contain the hybridisation intensities. Each gene or EST has been spotted in duplicate resulting in two intensities (`prim' and `sec') per hybridisation. The last two attributes are intended to take a local background value which is delivered by most of the imaging software packages. Three indices have been computed. `y1_g_589_ipr' and `y1_g_589_ise' facilitate the search for specific hybridisation intensities (`pr' and `se' for primary and secondary spots), `y1_g_589_isn' querying certain spot numbers.
Many imaging software packages yield more than one intensity score and background per spot. Commonly, they provide differently calculated intensities (eg. pixel mean, median), background intensities and various kinds of quality or reliability measures. From these, the contents of the above tables are either choosen or calculated as a starting point for standardized analysis in the process of database upload.
As experiments are analysed and valued, hybridisations are deleted e.g. for bad signal quality, written into another context or kept in the experiments and conditions they were uploaded in. When a set of hybridisations is not to be altered any more, it is solidified, that is written into large block tables over night, as mentioned in 2.2.2.The separation into the 5 spot categories is kept resulting in 5 block tables. Tuples of the above table will go e.g. into y1_g_block1.
|
Table = y1_g_block1 +----------------------------------+----------------------------------+-------+ | Field | Type | Length| +----------------------------------+----------------------------------+-------+ | tableno | int4 | 4 | | spotno | int4 | 4 | | prim | float8 | 8 | | sec | float8 | 8 | | prim_bkg | float8 | 8 | | sec_bkg | float8 | 8 | +----------------------------------+----------------------------------+-------+ Indices: y1_g_block1_ipr y1_g_block1_ise y1_g_block1_isn y1_g_block1_itn |
These tables have exactly the same structure as the normal hybridisation tables. The only difference is that an index was computed for the table numbers (named `y1_g_block1_itn') enabling rapid hybridisation wise retrieval of the tuples from the block. Such a block was tested with up to 538 hybridisations of the y1 type (comprising 6103 genes), speeding up retrieval of an entire multiconditional experiment up to 15fold compared to the unsolidified version depending on how many hybridisations are comprised, and on its position in the database.
For measurement-dependent annotations, structures mentioned for the condition dependent annotations (3.4.2) apply as well. The table y1_measurementdependent_65 containing the measurement-dependent annotations of multiconditional experiment 65 inherits from y1_measurementdependent and has the same structure as y1_conditiondependent_65 except for one additional attribute `measurement', which is related to the intensity tables by relation y1_experiment_65. `Condition' is related to `measurement' here as well to secure this important information by repeated storage3.1.
|
Table = y1_measurementdependent_65 +----------------------------------+----------------------------------+-------+ | Field | Type | Length| +----------------------------------+----------------------------------+-------+ | experiment | int4 | 4 | | condition | int4 | 4 | | measurement | int4 | 4 | | ano | int4 | 4 | | annotation | text | var | | vno | int4 | 4 | | cvalue | text | var | | nvalue | float8 | 8 | +----------------------------------+----------------------------------+-------+ |
Although all defined annotations have to be annotated for a multiconditional experiment, their distribution among the hybridisation-dependent, condition-dependent and constant database relations may vary from experiment to experiment. Annotation starts by choosing the annotations which shall become measurement-dependent and thereafter assigning a value to each of those annotations for each measurement. Thereafter, the condition dependent annotations are selected and annotated before the remaining constant annotations are entered. The annotation process is mediated by a web interface such that annotation can be performed from remote sites, enabling annotation even before uploading of intensities, re-editing of assigned values and copy from similar experiments to save the user from re-entering identical values.